In our latest article, Kaya ter Burg, Researcher on multi-modal underwater computer vision for litter detection at the TUDelft, shares insights about her work for SeaClear2.0, and the development of AI algorithms for marine litter localization and classification.
Read the full article below:
In the previous article, we talked about constructing a dataset with images containing marine litter, plants and animals. To quickly recap: we need such a dataset to train neural networks to automatically detect marine litter with the MiniTortuga, one of the key components of the SeaClear2.0 system. The MiniTortuga scans the seabed in search of litter. Both camera and sonar videos are collected and then processed into labeled images. The labeled images contain the location and the type of object for all litter, animals and plants occurring in the image.
Now that the dataset is fully curated and annotated, the exciting part can begin: training the neural network! The type of neural networks we need to use are those for object detection, which uses bounding boxes and class labels. Object detection is one of the main computer vision tasks and many different methods have been developed. For the SeaClear2.0 system, not only the detection accuracy is important, but also the speed of the networks. Since we want to be able to detect the litter immediately on the camera and sonar-feed of the MiniTortuga, we need real-time detection. Real-time object detection algorithms are able to predict the possible object locations and types quickly, so that we can directly see them on a video feed and proceed accordingly to collect the litter.
Training an object detection network involves processing the whole dataset over and over again, similarly to how humans learn a task by practicing it many times. Each time the network sees an image, it makes a prediction and compares that against the correct answer, also called the “ground truth”. This correct answer consists of the labels we made when constructing the dataset. When the prediction is compared against the ground truth, the network can see where the predictions still need to be improved and the network updates itself accordingly. This repeats until the performance is good enough and training is finished.
After completing the training, we now have a network that we can apply to new data, without the need for manual labeling. This enables the SeaClear2.0 system to be able to detect litter completely autonomously, so without any human intervention. In the video the predictions of one of our trained networks is shown.
As you can see, the network predictions are not perfect, some litter items are still missed. This means there is still room for improvement! Underwater computer vision is still relatively underexplored, especially compared to above-water applications. On top of that, the underwater world comes with many additional challenges. Visibility is often limited due to environmental circumstances, such as turbidity. Furthermore, marine litter objects are often small and can be covered or buried. This all makes it more difficult to do object detection.
However, there are ways to deal with these complications!
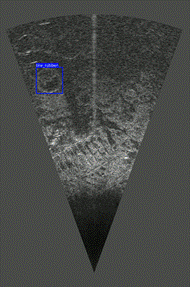
One of the things we’re currently focussing on is integrating sonar into the object detection pipeline. A camera has a high resolution, meaning it can visualize details well, but it struggles in the often-turbid underwater environments. A sonar, on the other hand, yields lower-resolution images, but is more robust against the underwater circumstances. By combining these two sensors, we can use their respective strengths while lessening their weaknesses. Overall, this results in more robust underwater object detection. In the two images, the same rubber tire is highlighted. In the camera image, the tire is almost invisible. However, in the sonar image, the circular shape of the tire is clearly visible! This shows how adding the sonar helps with detecting objects that would otherwise be missed.

For using both camera and sonar images simultaneously, we need to adapt the current network that only uses camera images. This once again starts with the dataset. During the SeaClear2.0 data collections, we collect both camera and sonar videos simultaneously. This ensures that we always have a pair of camera and sonar images taken at the same time. The network is adapted such that it processes both images and gives predictions based on the camera image and also on the sonar frame. Then these predictions are merged and we end up with a final prediction that takes into account both sensors. We are currently exploring different ways to do this, so that the network gets the best performance boost. Once this network is developed and integrated into the SeaClear2.0 system, we ensure that it is able to detect marine litter even more robustly, especially in turbid water.